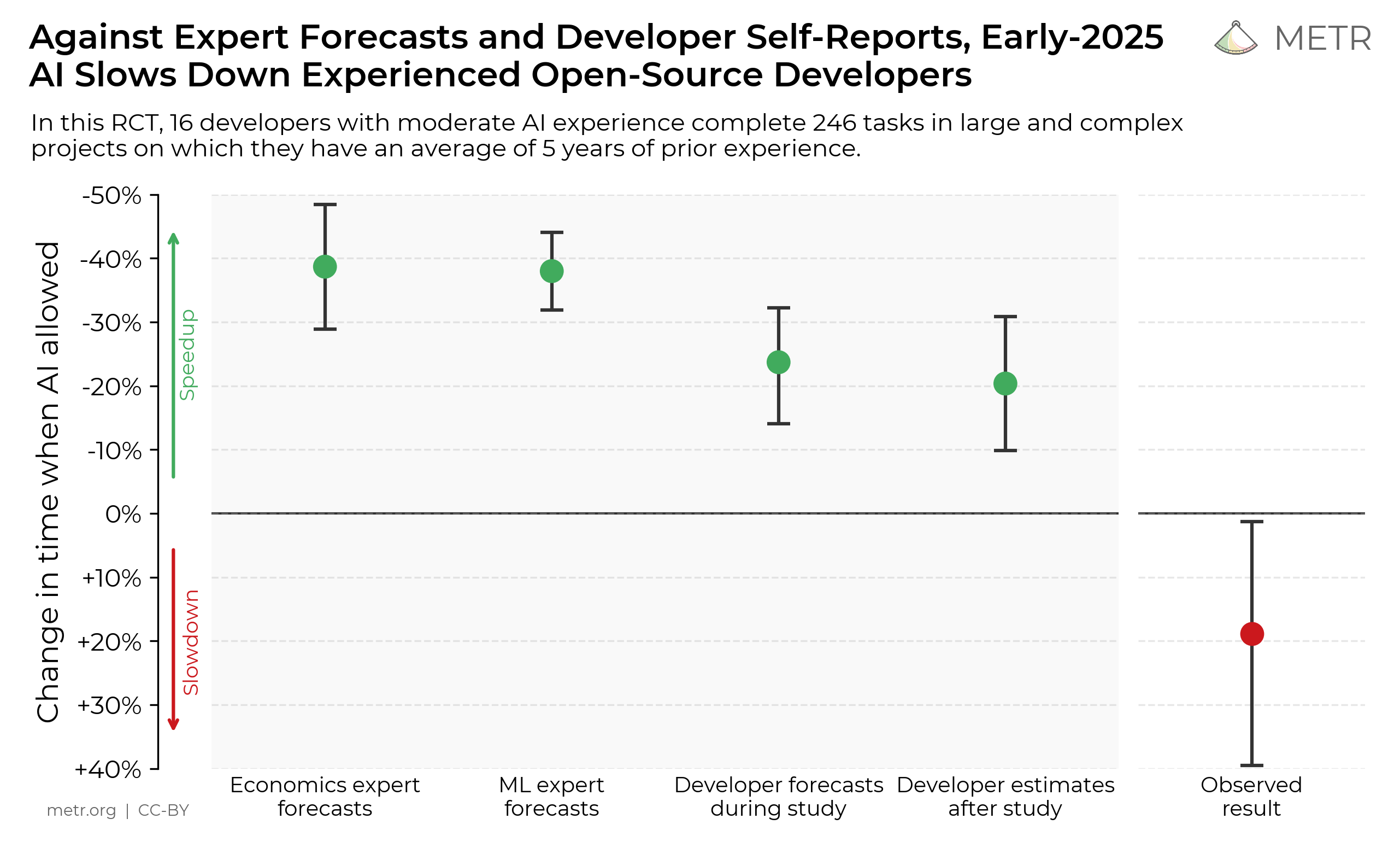
Recently, METR released a study which showed that engineers took 19% longer to complete tasks with AI than without. As someone who spends a lot of time experimenting with AI workflows, this was a scary result to read.
Even scarier than a mere slowdown, the results also demonstrated a negative effect on engineers' perception of their productivity. Despite actually being 19% slower, AI-tasks felt 20% faster.
AI coding tools have become very good in the last year. Many are claiming orders of magnitude productivity improvements. Sahil Lavingia is '40x-ing' his productivity. Tobi Lutke is watching employees 'get 100X the work done'. Intercom, conservatively, is aiming for a 2x productivity boost.
Yet, at the same time, the world does not seem to be producing 10x or even 2x as much quality software. What’s going on?
Where was AI slowing me down?
I decided to conduct an experiment. I came up with a simple plan: record my screen for a week, use AI as usual, then review the recordings to see what was happening1.
Watching yourself program is uncomfortable. Every mistake, every rabbit hole, every moment of distraction is painful to watch. As I winced through the recordings, I noticed a particular AI anti-pattern emerge.
Spend time clearly specifying a task for the AI.
Dispatch the agent.
Wait for the agent. Not really know what to do with myself. Check Slack.
The agent completes 80% of the task.
Review the code, provide feedback, and highlight issues.
Re-dispatch the agent.
The agent still doesn’t quite succeed.
Manually intervene to fix the remaining issues.
Manually test the work to ensure I trust it.
At the time, I perceived the AI as a real speed-up. Auto-generating 80% of the result feels productive. Looking over the cold, hard data, it’s clear I was going in circles. I still had to rely on my brain power and review time to get the results I needed.
While the agent is saving me some work by typing out code, I’m still investing time in the problem. First, I’m writing a specification. Agents need more context than I do, so I spend valuable minutes agent fluffing. I point to example files, explain patterns I already understand, and try to wrangle the agent into a style I myself would follow naturally. Really, I need to understand the problem before I can even do this step effectively.
My day-to-day work is in a similar context to the METR study. I have 7 years of experience and I'm working in a large codebase with high standards. Worse, this codebase is closed source and uses a series of unconventional technology choices and internal libraries. No shadcn boilerplate for me.
Making AI-powered changes in such an environment, while not impossible, is challenging. Even with a clear spec, your agent will misfire. Agents are relatively fast at making text edits,2 but what I saw in my recordings was that they make the wrong edits.
The deficiencies of LLM-generated code are often subtle. I usually have the sense that the code is 80% there. I'm sure some people merge 80% code but for my team this isn't good enough. 80% is effectively 0%; it's not shippable.
An agent implementing even a relatively simple backend change in our codebase will need to know how we…
Write logs
Instrument spans
Use our custom ORM
Handle errors
…and a thousand other details.
Details like these are the difference between shippable and un-shippable code. My agents were landing firmly on the un-shippable side.
I would catch many of these errors at review time, but the error rate meant I was getting bogged down. An external perspective can be helpful, but when you didn’t implement the change yourself, you need to gain context. Context acquisition and high error rates make reviewing LLM-generated code slow and painful.
By this point, you’re subject to context rot. You’ll be pushing the agent to do more than it is capable of and performance will begin to degrade. I saw my agent playing whack-a-mole with the bugs and never quite get across the finish line. I needed to manually intervene.
When I pair with skilled engineers, their workflow is often the opposite of this smash and fix flow. They calmly consider the situation. They build the right mental model. When they understand the problem, only then do they write the implementation. Any bugs that are encountered are used to update the mental model and implement clean, systematic fixes.
AI-generated psychological damage
I fear these tools are brainrot, that each agent dispatch takes me further away from this skilled engineer mindset.
The METR study presents several theories for the observed slowdowns. Two that stood out to me were “over-optimism about AI usefulness” and “trading speed for ease”. The interesting thing about these theories is that they have nothing to do with the AI itself; they’re about the developer’s psychological interaction with the task.
AI coding is problematically exciting. The 5% of tasks that AI one-shots feel incredible. But if you're not careful, you can end up doing dopamine-driven development. You need your AI fix. Just one more prompt.
I think this feeling prolonged my agent threads past the point of productive returns. Like a slot machine user, I hoped the next prompt would be the one that finally got me my reward. At some point, I had to step back and finish the job myself.
I don’t think I’m there personally, but I’ve heard reports of Cursor ‘one-shotting’ previously productive devs. Something about tasting that AI-driven high messes with your ability to think about things in depth. It’s doomscrolling for coding.
Another psychological trap to watch out for (and that I witnessed in my recordings) is that async agents can leave you susceptible to distraction. Rather than remaining in a continuous flow, you open up windows of distraction as you wait for each task to finish. The METR study recorded that developers spend 4% of their time waiting. Not catastrophic, but if you view that 4% as a window to open Slack, email, or Twitter, things start to look a lot worse.
Where was AI speeding me up?
I’ve painted a rather gloomy picture of AI productivity so far. Let’s look at some examples of where AI did speed me up.
Example 1: Generating bash commands
I’m a big fan of the GitHub Copilot CLI. It seems to be the most underrated AI tool at the moment. I’ve used it to setup an alias (??) that generates bash commands from natural language, saving me time trawling through man pages and Stack Overflow.
$ ?? Revert merge commit
Suggestion:
git revert -m 1 <merge-commit-hash>Example 2: Writing a log query
We’ve recently started using a new logging tool which uses a query language I’m unfamiliar with. While not difficult per se, I can’t yet write queries in this language fluently. AI, on the other hand, has read everything there is to know about query languages and can write my code in seconds.
Example 3: Fixing environment issues
At one point, I had a non-obvious issue with my nvm config and Claude Code one-shotted it. Any problem that requires trawling through logs, config, or other text files and quickly pattern matching is a good fit for AI.
Example 4: Prototyping API interfaces
When AI writes 80% code, I cannot ship it. However, not all code needs to be shipped; sometimes you just need to try something out.
A lot of my work focusses on public APIs. Here, it's not only important to get the API implementation right, but also the interface. I had tremendous success with Claude Code prototypes that, while buggy and un-shippable, let me quickly test API usability.
Example 5: Architecture grokking
Sometimes, you encounter a new part of the codebase and need a quick, general understanding. Claude Code is very good at providing quick architecture summaries (including Mermaid diagrams if you ask) and they’re almost always single-prompt tasks.
What are the patterns?
In general, a problem that worked well for AI was one where:
The problem was text-based.
Relevant data were in the training set.
Either a throw-away solution would do, or the problem was well-scoped.
This is quite a contrast to the full feature implementation tasks my agents struggled with.
How do I evaluate these productivity gains? In isolation, it seems reasonable that I was getting a 2-10x boost from the AI. Nothing in this list would be impossible without AI, but I saved a lot of Googling, reading and tedium.
The overall picture is harder to reason about. I’ve been visualising these speed-ups as a Pac-Man game. The AI acts like a speed-boosting power-up that lets Pac-Man move 5x faster. But the power-ups don’t magically steer you round corners and automatically take you out of danger. You can’t just say ‘escape from the ghosts’ and be done with it. You still need to work out the plan yourself.
Working in an AI-first environment
The limitations I encountered in my day job made me wonder what would happen if I set up everything just right for the AI. Could the high-level execution that failed in a large, legacy codebase work if done in an AI-native environment? Another experiment was in order.
I've been playing with a small side project that aims to be as AI-friendly as possible.
The project is a greenfield, conventional client and server web app.
The stack is as vanilla and 'in the training set' as possible: Python, FastAPI, Postgres, Next.js, Tailwind, shadcn. If in doubt about what tech to pick, I ask the AI and go with its preferred tool.
The backend is in Python, a language I've only dabbled in, thus providing me with greater speed-ups as AI teaches me the language and writes idiomatic code.
Everything is tested, linted and formatted automatically via Claude/git hooks.
There are AI-legible markdown files for everything: specs, tickets, docs, READMEs, CLAUDE.md.
With a project designed from the ground up for AI, it turns out I'm able to execute on an end-to-end AI workflow quite effectively.
Define a minimal spec manually (usually dictated with superwhisper).
Get GPT-5/Opus 4.1 to turn this into a detailed design doc.
Use AI to break this down into clear tickets, specified in markdown files.
Spin up new agents to implement the tickets. Parallelise the work where possible.
Use separate agents to automate test generation.
Auto-fix any test failures.
Write AI-generated docs for the new feature when done.
This setup works very well. The rework rate is noticeably lower than on my day job. Working on boilerplate code and config felt almost instantaneous. Claude and GPT-5 are competent at designing stock parts of an application such as authentication and database setup. As I design clearer architecture patterns, add more tooling and practice my 'multi-Clauding', I only expect my progress to accelerate.
However, things are not perfect. Two limiting factors stand out.
First, you still need to decide what you're going to build and when to build it. You need to know what the important parts of your product are and the right order of execution. AI is not particularly helpful here. You need to bring your own taste and product context.
Next, you still need to be able to evaluate architectures. When a spec is generated, it is usually imperfect. You need to be able to review designs and provide feedback to improve them. You also need to understand what's happening so you can review code and catch errors at the implementation stages.
As an experienced product engineer, these challenges are surmountable. Without a background in building products, you’ll likely have more trouble.
Making legacy environments AI-first
If this AI-first setup works so well, why don’t we replicate it in legacy contexts?
My playground app is greenfield and has one user (me). I’m not exactly facing scaling challenges without a domain name. AI is OK at system design at this scale. However, start to work at the scale of my data-heavy, Series B startup day job and it’s an entirely different game.
There's a similar story with craft and quality. AI will churn out an OK UI. However, you won't achieve the quality level of the greats. Claude will not care and it will not invent. You'll get there quicker, but your results will always be just fine.
For my side project, I’m choosing to ship a worse UI at a faster AI-driven rate. Does this trade-off make sense for serious projects? I don’t think so. Successful companies need to be best-in-category. Customers choose the best product. You can’t opt out of scaling or quality.
Running downstairs
In “How to Make Wealth”, Paul Graham suggests that startups must choose the harder path to succeed.
At Viaweb one of our rules of thumb was run upstairs. Suppose you are a little, nimble guy being chased by a big, fat, bully. You open a door and find yourself in a staircase. Do you go up or down? I say up. The bully can probably run downstairs as fast as you can. Going upstairs his bulk will be more of a disadvantage. Running upstairs is hard for you but even harder for him.
The difficulty is that AI is currently only making the easy parts easier. I can run downstairs faster, but going upstairs is just as hard as it ever was.
Creating new things, scaling codebases, the messy, knotty work of product—all the stuff that truly makes companies successful—it’s all still hard. AI speed-ups pale in comparison to working on the right things, engaging deeply with the problem at hand, and not wasting your time on bullshit.
What are we to do?
I have made a lot of updates to my behaviour due to these experiments. Primarily, I’m going to stop trying to get LLMs to implement features for me and focus instead on scoped usage of AI for what it’s best at: information gathering, text and leveraging the training set.
Less tactically, this is all a stark realisation that the hard things need more focus than ever.
If you have any experiences contrary to the findings in this blog post, I would be very keen to hear from you. In particular, please email james - [at] - productengineered.com if you are having success using agents to autonomously build apps in the top percentile of quality or with serious engineering challenges.
rewind.ai is a "personalised AI powered by everything you've seen, said, or heard." While the claims about being able to "Ask your AI anything" seem to be pure fantasy, this app has a feature that I found very valuable for investigating my productivity. Rewind will record everything that happens on your screen, compress it and store it locally. This gives you weeks or even months of data about exactly what you were doing, every minute of every day. You scroll along a timeline and see everything that was on your screen.
I have set up small races and they are a touch faster than me and my 100wpm and Vim keybindings.